Redis核心数据结构与单线程原理
Redis核心数据结构
Redis是属于key-value结构,value可以存储的数据结构非常多,在工作中常用的有以下5种:

- String(字符串)
- Hash(哈希字典)
- List(列表)
- Set(集合)
- Zset(有序集合)
其中,list、hash、set、zset这四种数据结构属于 容器数据结构,共享以下两条通用原则:
- 容器不存在则自动创建
- 如果容器中没有原则,则自动删除容器并释放内存
String(字符串)
String内部结构
String是Redis最简单也是最广泛使用的数据结构,其内部是一个数组:

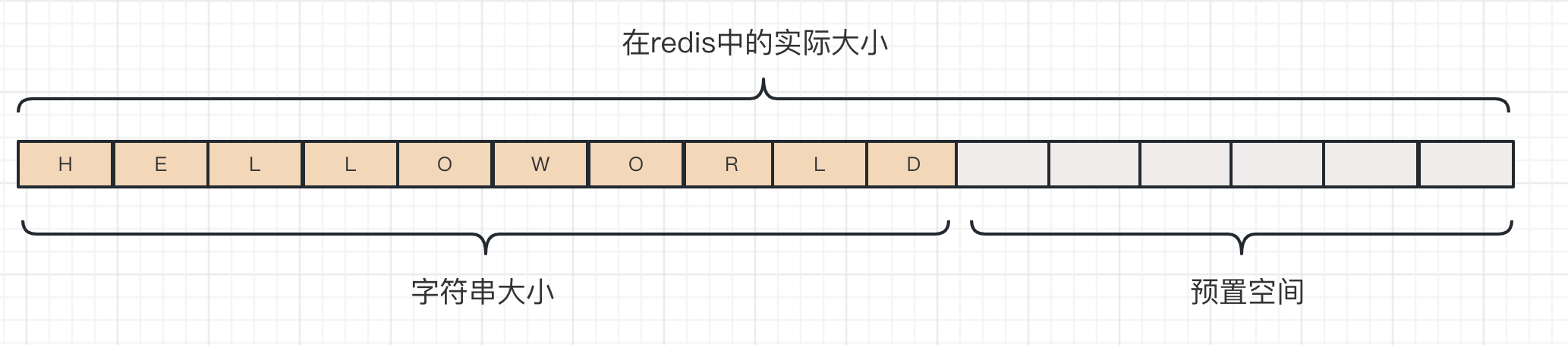
Redis中string(字符串)是动态字符串,允许修改;它在结构上的实现类似于Java中的ArrayList(默认构造一个大小为10的初始数组),这是冗余分配内存的思想,也称为预分配;这种思想可以减少扩容带来的性能消耗。
String扩容
当string(字符串)的大小达到扩容阈值时,将会对string(字符串)进行扩容,string(字符串)的扩容主要有以下几个点:
长度小于1MB,扩容后为原先的两倍; length = length * 2
长度大于1MB,扩容后增加1MB; length = length + 1MB
字符串的长度最大值为 512MB
常用操作
1 | // 单值操作 |
使用场景
单值缓存
1 | localhost:1>set love 1 |
对象缓存
在字符串中进行对象缓存有2种方法:
把 entity对象转成JSON字符串后,进行单值存储
通过批量存储字符串键值对的方式(批量缓存)
1
2
3
4
5localhost:0>mset user:1:usenrame zhangsan user:1:age 20
"OK"
localhost:0>mget user:1:usenrame user:1:age
1) zhangsan
2) "20"
为什么推荐 批量存储字符串键值对的形式 来缓存entity对象?
- 当我们需要去修改 Redis存储的对象字段内容的话
- 第一种:必须先把整个JSON字符串提取出来后,转成对象后再修改字段,再转成JSON字符串存进去
- 第二种:因为是单独的去存储每个字段,所以可以直接单独修改每个字段内容,相对第一种 效率提高了很多
过期set命令
- 通过给缓存key设置过期时间,使缓存到期后会自动删除 过期的key
方式一:先创建key,对key设置过期时间
1 | // expire key seconds |
方式二:创建key的同时设置过期时间
1 | // setex key seconds value |
计数器
string也可以用来做计数器,但前提value必须是整数,自增范围区间:[-9223372036854775808,9223372036854775808]

我们可以在浏览一次后,就在redis中进行一次计数,用于做 阅读量、点赞量等计数器。
incr -> 自增1
1 | localhost:0>INCR article:1 |

incrby -> 自定义累加值
1 | localhost:1>set test:1 20 |

测试value为整数的自增区间
1 | // 最大值 |
Hash(哈希字典)
Redis的hash(字典)相当于Java语言中的HashMap,它是根据散列值分布(哈希计算)的无序字典,内部的元素是通过键值对的方式存储。
它的数据结构也是数组+链表组成的二维结构,节点元素散列在数组(哈希桶)上,如果发生hash碰撞则使用链表串联在数组节点上。

Hash(字典)扩容
- Redis中的hash存储的value只能是字符串
- Java中的HashMap 扩容是一次性完成扩容的,而Redis考虑到单线程性能问题,采用的是渐进式扩容,多次完成
- 渐进式扩容:需要扩容时会拷贝一个新的hash结构,在rehash(扩容)结束后,会把旧的hash数值同步到新的hash,并删除旧的hash,用新的hash来代替旧的hash。
常用操作
1 | HSET key field value //存储一个哈希表key的键值 |
使用场景
对象缓存
前面提到过,redis是kye-value的形式,而哈希本身也是key-value的形式,前面有提到过用字符串来缓存entity对象,同样哈希也是可以缓存entity对象的。


1 | // 存储语句分析 user:redis key 1:.... 为哈希key ,zhangsan:哈希value |
电商购物车
在电商系统可以通过redis快速的实现购物车功能,性能、效率比直接操作数据库更快。
redis实现京东购物车
下面我们将通过一个小示例,通过redis实现京东购物车功能:

字段解释:

如:card:1 10001 1
以 card+用户ID 作为redis的key,商品ID为field(字段名,哈希内层key),商品数量为value(哈希内层value)
购物车操作
1)添加商品到购物车
1 | // 使用hset时,如果key已经存在,则会更新数据(返回0),如果不存在则会新建该键值对(返回1)。 |
2)增加购物车商品数量(hincrby)
1 | localhost:1>hincrby card:1 10001 5 |
3)获取购物车商品总数量
1 | localhost:1>hlen card:1 |
4)从购物车中删除某商品
1 | localhost:1>hdel card:1 10001 |
5)获取购物车所有商品
1 | localhost:1>hgetall card:1 |
Hash优缺点
优点
- 方便同类数据归档整合存储,方便数据管理
- 如:存储entity实体对象
- 相较于String 操作消耗内存和CPU更少,且比String 更节省空间
缺点
- 过期功能不可用用在field(Hash内层Key)上,只能用在Redis 外层Key
- 要嘛就是整个key过期,哈希内层的field 字段是不可以加倒计时的
- Redis集群架构下不适合大规模使用
- 因为哈希结构的数据是一个完整的结构,如果在集群架构下使用Hash结构的Redis,很容易造成 数据倾斜
数据倾斜

假设我们现在有个entity 实体类(user),如果通过Redis集群存储,因为数据分片存储,只能挑其中的某个节点,那么其他的节点是没有这个entity数据的,这就是 数据倾斜,如果大量的用户来访问该数据时,请求都会走到该节点中,该节点的压力会非常大。
解决数据倾斜方案:分段存储
把存储的entity通过某些特定的规则,均匀的分段存储在不同的Redis节点。
List(列表)
List 底层结构
Redis的列表相当于Java语言中的LinkedList,它是一个双向链表数据结构,支持前后顺序遍历。链表结构插入和删除操作快,时间复杂度O(1),查询慢,时间复杂度O(n)。

Redis底层存储list(列表)不是一个简单的LinkedList,而是quicklist ——“快速列表”,quicklist是多个ziplist(压缩列表)组成的双向链表。
ziplist
- ziplist是一块连续的内存存储空间,他们之间无需持有prev和next指针,能通过地址顺序寻址访问。

redis底层在存储List元素时,当元素个数少的时候,它会使用一块连续的内存空间来存储,这样样可以减少每个元素增加prev和next指针带来的内存消耗,最重要的是可以减少内存碎片化问题。
quicklist
- quicklist是由多个ziplist组成的双向链表。

常用操作
1 | LPUSH key value [value ...] //将一个或多个值value插入到key列表的表头(最左边),往key列表最左侧插入数据 |
使用方式

Stack(栈)
- 栈在结构上是先进后出(FILO)的数据结构(比如弹夹压入子弹,子弹被射击出去的顺序就是栈),这种数据结构一般用来逆序输出。
LPUSH 左侧入栈小实验

1 | // 从左侧入栈 |
Queue 队列
- 先进先出原则,类似于MQ(LPUSH + RPOP)
1 | localhost:1>LPUSH admin 1 |

Blocking MQ(阻塞队列)
- 当你的队列中没有数据时,我们可通过 阻塞命令获取,那他就会一直阻塞住队列,直到 时间s超市(阻塞设置了超时时间),或有数据进入队列为止。
1 | BLPOP key [key ...] timeout //从key列表表头弹出一个元素,若列表中没有元素,阻塞等待timeout秒,如果timeout=0,一直阻塞等待 |
使用场景
List的使用场景很多,需要自行去思考,去尝试和实践,下面介绍一种比较常见的玩法。
订阅号消息
这里我们订阅了《中国联通》和《人在厦门》的公众号,他们会对我们进行推送消息。

在我们程序员来看,实现该功能有多种方法,有两种是比较常见的。
- 《中国联通》发表文章后,系统主动的去push 通知给关注他的人
- 如果粉丝较少,主动push到redis中还可以接受,如果粉丝较多,达到数十万 数百万,主动去push的话,对redis的压力太大,为此我们可以考虑做出一定的优化,例如 只push在线的粉丝,没在线的粉丝可以通过 第二种方式主动去pull 拉去通知
- 粉丝客户登录APP后,主动去拉去 他关注的 公众号的文章
实现过程:

- 《中国联通发表文章》–> redis操作: LPUSH msg:{关注该公众号的粉丝-ID} 文章ID – >
LPUSH msg:2200919 991029193 - 客户上线后,需要查看该列表 –> redis操作:LRANGE msg:{粉丝-ID} 0 4 ;「0 - 4 读3个,0 、 1 、 3 ,index是从0开始」
LRANGE msg:{粉丝-ID} 0 4
Set(无序集合)
redis的set 类似于Java的HashSet,set内部的键值对是无序且唯一的,当set集合中最后一个元素被删除时,集合会自动删除,回收内存。
常用操作
1 | Set常用操作 |
应用场景
由于set具备去重(唯一性)功能,在生产环境中的应用场景非常多,这里只举两个个例子:微信抽奖小程序和朋友圈点赞。
微信抽奖小程序

因为set是不会重复的,那我们在使用set集合来做抽奖活动时候,key可以存储活动项目ID,value可以存储参与抽奖用户的ID。
1 | // 参与抽奖命令 存储 活动ID 和用户ID |
参与抽奖命令

查看参与抽奖的用户数量和查看所有参与抽奖的用户列表

两种抽奖模式

朋友圈点赞
类似于点赞、收藏等都可以使用redis的set集合来实现。

1 | // 点赞 SADD like:{朋友圈消息ID} {用户ID} |

集合操作

前置条件:创建set1、set2、set3
1 | localhost:1>SADD set1 a |
交集
1 | localhost:1>SINTER set1 set2 set3 |
如上图所示,取set1、set2、set3 三个集合中 共同的元素,这里共同的元素 是C。
并集(合集)
把set1、set2、set3 三个集合 合并后去重的结果就是并集。
1 |
|
差集
1 | localhost:1>SDIFF set1 set2 set3 |

以 set1为基准,求出 set1 与 (set2 和set3) 的差集,简单理解:
公式:set1 - { set2 + set3 并集 } –> {a,b,c} - {b,c,d,e} = 基于set1 (set2 和set3) 的差集是a
集合实现微博、微信关注模型

- 通过集合也可以实现微信、微博的关注模型,但切记 这只是更多的是提供一种思路,不论什么实现方式只要涉及到了大数据量量和高并发,肯定有其他更优解,更优秀的优化方案。
微博关注模型
名词理解
共同关注的人:现在你查看的那个人也有关注你关注的人
- 我关注了支付宝官微,支付宝官微也关注了我 关注的人
我关注的人也关注她:是我关注的人也关注了你当前查看的人
- 我关注了其他人,其他人也关注了 支付宝官微
创建关注关系
关注名人:张柏芝(zbz)、王宝强(wbq)、周杰伦(zjl)、王杰(wj)、陈凯歌(ckg)
张柏芝关注:王百强、王杰
1 | localhost:1>SADD zbzSet wbq |
陈冠希关注:张柏芝、王百强
1 | localhost:1>SADD chenguanxiSet zbz |
陈奕迅关注:周杰伦、王杰
1 | localhost:1>SADD chenyixun zjl |
陈小春关注:陈凯歌、张柏芝
1 | localhost:1>SADD chenxiaochun ckg |
查看 陈冠希与陈小春共同关注:
1 | localhost:1>SINTER chenguanxiSet chenxiaochun |
我(陈冠希)关注的人也关注他
- 陈冠希此时在看(关注)的人是王宝强,查询 陈冠希关注的人里面,有没有也关注了王宝强的
1 | localhost:1>SISMEMBER zbzSet wbq |
可能认识的人(查询差集)
1 | // 以 陈冠希为基准,查询陈冠希与 陈小春的差集 |

ZSet(有序集合)
zset是redis中比较常使用到的数据结构,zset既保证了数据唯一性(不可重复),也可以通过 value的score 权重来实现排序。该排序功能通过Skip List(跳跃列表)来实现的。
当zset集合中最后一个元素被删除时,集合会自动删除,回收内存。
利用ZSet的去重和有序的特性,一般用于做排名、排行榜,如 微博排行榜、学生成绩排行榜等。
常用操作
1 | ZADD key score member [[score member]…] //往有序集合key中加入带分值元素 |
ZSet实现微博排行榜

我们可以使用ZSet实现微博排行榜(或其他排行榜),用户在每次搜索一次新闻,都会把该新闻作为key添加一次 记录。
1 | // 添加搜索新闻 |

Redis单线程
redis真的是单线程吗
redis并不是完全意义上的单线程,具体的看是客户端读写请求还是其他功能,如果是客户端读写则是单线程,其他功能有额外线程。
redis的单线程主要指的是 客户端发起的请求命令(键值对读写)是由一个线程完成的,但redis的其他功能,如 持久化、异步删除、集群数据同步都是有其他额外线程执行。
redis单线程执行效率快的原因
- redis 数据都存储在内存中且数据运算都是在内存中进行,相比较MySQL 在磁盘中速度快得多。
- redis持久化肯定不是实时存储到硬盘,而是有一个时间周期,否则redis的性能会急剧下降
- 多线程切换存在 线程损耗的问题, 单线程就完美的避免了线程损耗,但对一些比较耗时的命令,需要慎重使用,避免线程卡顿
redis单线程如何处理并发客户端
redis单线程的情况下还可以处理那么多的客户端并发请求,只要靠的是 IO多路复用机制。

IO多路复用机制
- redis利用epoll来实现IO多路复用,将连接信息和事件放到队列中,依次放到文件事件分派器,事件分派器将事件分发给事件处理器。
用人类的语言(说人话)说就是,redis对客户端的处理毋庸置疑是单线程模型,只是他会把多个请求同时放在一个队列中,然后放到事件分派器中,让分排期进行任务调度。
- S0 S1 S2 S3客户端同时发起读写请求,redis把他们都存入队列中发送给分派器
- 根据队列先进先出原则,S0会先执行,在执行的过程中肯定有一定的IO等待时间(哪怕很短),那么分派器在等待的过程中会让队列中下一个客户端请求 如 S1 先去执行他的命令。
redis 简易单机压测
我们可通过redis自带的一个小工具,进行简易的 get、set 压测,看看当前单机的一个QPS吞吐量。
1 | cd /www/server/redis/src |
redis支持的最大连接数
在redis.conf文件中可修改(不建议修改),# maxclients 10000
1 | localhost:1>CONFIG GET maxclients |
redis另类高级指令
keys 全量遍历
类似于mysql的findAll,一次性遍历出redis所有的key(不含value),当redis数据量较大时,性能会很差,在生产环境谨慎使用。
1 | localhost:1>keys * |
scan 渐进式遍历
在大数据量的情况下,一下子遍历出所有的key会非常消耗CPU和内存资源,这明显是非常不理智的行为,为此 redis准备了另外一个命令 scan 渐进式遍历,他可以慢慢的 遍历出 整个redis的key。
scan缺点
- 在使用scan遍历的过程中有数据变化(增加、删除、修改),很可能出现数据不精确(或不完整)的情况。
- 在scan遍历过程中,新增的键如果被分配到了 遍历过的桶上面,redis不会在从头遍历,结果集就没有新增的键
redis存储结构
redis内部结构类似于哈希结构,存储一个数据时,会根据key 进行哈希算法计算,计算出cursor 浮标(哈希桶的位置),找到cursor浮标位置,存储在浮标的哈希桶中,同一个哈希桶的多个数据则由链表结构进行维护。

上面提到的scan缺点,如果我们在使用scan开始遍历时有数据变化,如 新增数据(分配到了第一个桶),可是此时 如果已经遍历到了第四个哈希桶,则不会再回头去遍历,这样就会丢失掉部分数据。

scan命令
scan 0 match test* count 3 –> scan {cursor} match {param} count 3
cursor(浮标、光标)是哈希桶的索引值,param是要查询的值,count后面是遍历参考值(只是大概,这里为3,大概获取3条数据),类似于分页
1 | localhost:1>SADD test1 1 |




